




I. Introduction▲
Lorsque l'on commence un projet Talend, il est parfois difficile de savoir par où commencer et on s'aperçoit trop tard qu'on aurait dû définir plus de variables de contexte, plus de schémas… Du coup on revient sur les développements et la perte de temps qui en découle peut, dans certains cas, être critique pour un projet.
Que ce soit avec Talend Open Studio (TOS : version Open Source) ou Talend Integration Suite (TIS : version payante collaborative), il convient d'organiser dès le début l'espace de travail de façon optimisée pour la suite des développements.
Ce tutoriel va donc vous expliquer pas à pas comment bien commencer un projet avec Talend. Tous les exemples seront tirés de la version gratuite TOS 3.2.1, mais la méthode est approximativement la même avec TIS ou d'autres versions de TOS.
II. Configuration matérielle▲
Pour utiliser le client Talend, il faut savoir qu'il se base sur une plateforme Eclipse. Cette plateforme est très gourmande en CPU et en mémoire vive.
Préférez des postes avec au minimum :
- un processeur double cœur cadencé à 2GHz ;
- 2Go de mémoire ;
et si vous êtes sous TIS :
- idem qu'avant (voire plus de mémoire) ;
- connexion gigabit (pour mettre à jour plus rapidement le workspace partagé) ;
- disque dur 7200tr/min (pour accélérer la lecture/écriture).
Plus votre poste sera performant et plus vous chargerez rapidement le client Talend au démarrage, développerez et exécuterez vos jobs (en phase de tests).
III. Les environnements de travail▲
Tout d'abord, il est nécessaire de définir les environnements de travail. Par là, je veux parler des trois, voire quatre environnements qu'on peut trouver sur un projet, à savoir : l'environnement de développement (DEV), de préproduction (PREPROD) et de production (PROD). Vous pouvez bien évidemment en définir plus suivant vos besoins, par exemple un environnement de performance (PERF) où serait testé le projet avec un maximum de données pour vérifier que la montée en charge se déroule correctement.
Une fois ces environnements définis, il faut maintenant faire une liste de toutes les variables, noms de fichiers, accès aux bases de données, ftp, ssh… qui seront utilisés dans le projet suivant l'environnement dans lequel on se trouve.
On peut d'ailleurs le faire sous forme de tableau, ce qui permet d'avoir une vision globale de tout cela :
|
Variable |
Description |
Default |
DEV |
PREPROD |
PROD |
|---|---|---|---|---|---|
|
serverAddress |
Adresse du serveur |
localhost |
192.168.3.1 |
srv1-preprod |
developpez.com |
|
projectFolder |
Racine du projet |
C:/tests/ |
//192.168.3.1/appli/dev/ |
//srv1-preprod/ |
/appli/myProject/ |
|
binFolder |
Dossier contenant les binaires de l'application |
bin/ |
bin/ |
bin/ |
bin/ |
|
logFolder |
Dossier de logs |
log/ |
log/ |
log/ |
log/ |
|
inFileFolder |
Dossier des fichiers source |
in-file/ |
in-file/ |
in/ |
in/ |
|
outFileFolder |
Dossier des fichiers cible |
out-file/ |
out-file/ |
out/ |
out/ |
|
SshUsername |
Login SSH |
test |
jsd03 |
bob |
dupont |
|
SshPassword |
Mot de passe SSH |
testPasswd |
myPasswd |
secret |
verySecret |
|
SshPort |
Port SSH |
22 |
22 |
22 |
23 |
|
SshHost |
Nom d'hôte / IP du serveur SSH |
192.168.3.2 |
192.168.3.2 |
192.168.4.5 |
developpez.com |
|
FtpUsername |
Login FTP |
testFt |
jsd03 |
ftpPreprod |
ftpProd |
|
FtpPassword |
Mot de passe FTP |
testFTPpwd |
myFtpPasswd |
sec |
vSec |
|
FtpHost |
Nom/IP du serveur FTP hôte |
ftp-test |
ftp-dev |
ftp-preprod |
ftp-prod |
|
DBHost |
Nom du serveur de base de données |
localhost |
192.168.3.1 |
serv-preprod |
developpez.com |
|
DBUsername |
Nom d'utilisateur de la base de données |
DBTest |
DBdev |
DBpreprod |
DBProd |
|
DBPassword |
Mot de passe de la base de données |
DBpwd |
DBpwd |
DBpwd |
DBpwd |
|
DBPort |
Port de la base de données |
3306 |
1290 |
1551 |
1551 |
|
Paramètres additionnels de la base de données |
Paramètres additionnels de la base de données |
noDatetimeStringSync=true |
charset=UTF-8 |
charset=UTF-8 |
charset=UTF-8 |
|
DBBase |
Nom de la base de données |
DEV |
XE |
PREPROD |
PROD |
|
RefFileName1 |
Nom du fichier de références |
ref_users.csv |
ref_users.csv |
ref_users.csv |
ref_users.csv |
|
… |
… |
… |
… |
… |
… |
Plusieurs choses à retenir par rapport à ce tableau.
J'ai rajouté volontairement une colonne pour un environnement nommé « Default ». Car Talend, par défaut, enregistre toutes les variables d'un projet dans le contexte (environnement) « Default ». Il servira, dans notre exemple, pour définir l'environnement local du développeur (très pratique pour les phases de tests).
Dans le tableau j'ai ensuite ajouté les informations sur l'architecture logicielle du projet : dossier de log, les binaires… Puis les accès à un serveur SSH et FTP.
Pour terminer, j'ai aussi ajouté un nom de fichier où se trouvent certaines références qui seront utilisées par exemple en lookup de certains jobs et dont le nom est fixé par avance.
Vous pouvez ainsi lister toutes les informations qui ne varieront pas tout au long du projet et dont vous vous servirez de façon répétitive.
IV. Ajout des variables de contexte▲
Les variables étant maintenant listées, nous allons les ajouter au projet en les organisant par groupe de contexte.
Pour cela, faites un clic droit sur « Contextes » dans le menu de gauche. Puis sélectionnez « Créer un groupe de contexte »
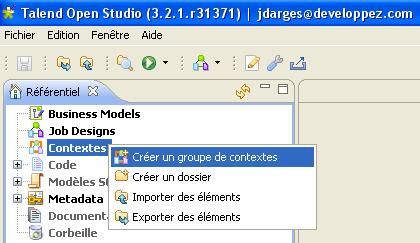
Pour commencer, on va ajouter les variables concernant les informations relatives au serveur en créant un groupe de contexte nommé « server ».
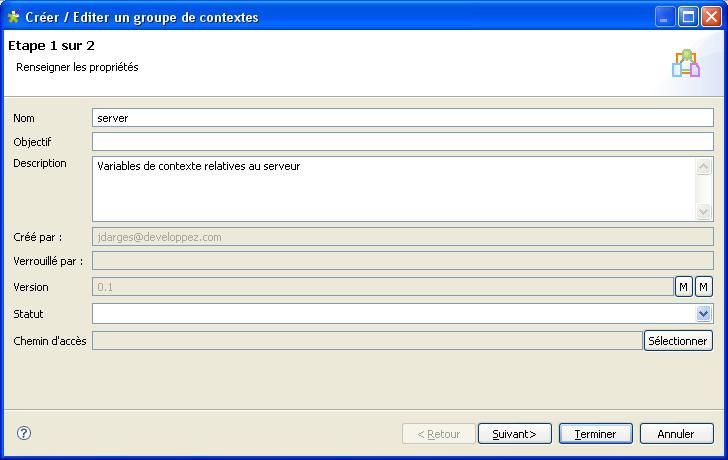
Vous pouvez voir que l'on peut modifier le type de données renseignées (String, int, boolean…)
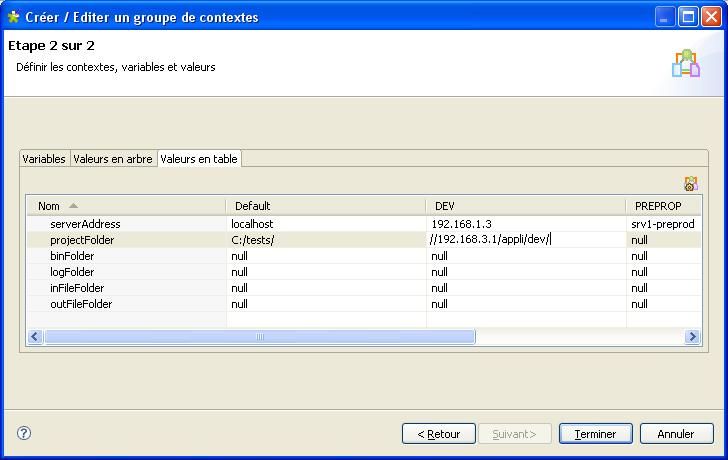
Cliquez maintenant sur l'onglet « Valeurs en table ». C'est ici que l'on va définir les valeurs des variables.
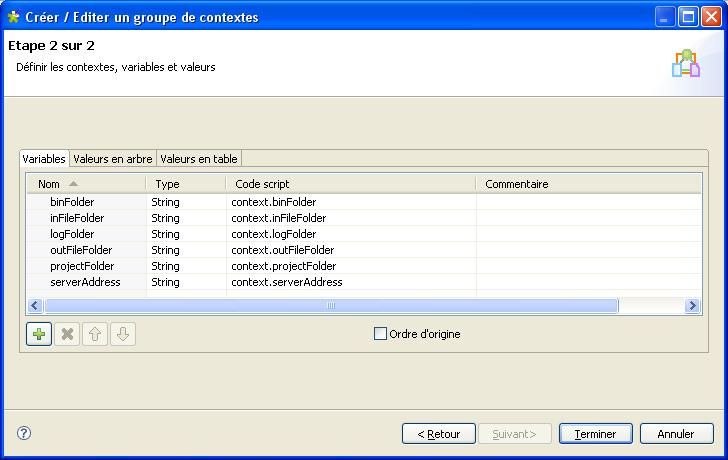
Nous n'allons pas définir tout de suite les valeurs des variables, mais ajouter les trois environnements que nous avons mentionnés plus haut en cliquant sur le bouton entouré en rouge sur l'image ci-dessous.
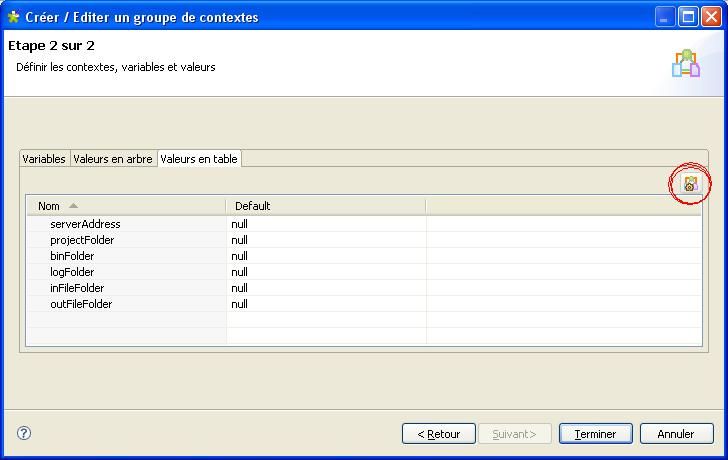

Une fois que vous aurez cliqué sur OK, Talend va ajouter autant de colonnes que d'environnements renseignés.
Pour changer d'environnement lors de l'exécution d'un job, allez dans l'onglet « Exécuter » et choisissez le contexte voulu.
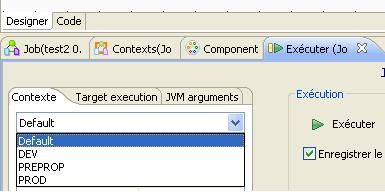
Vous pouvez maintenant reprendre votre liste de variables et ajouter les valeurs.
Le groupe de contexte « server » va s'ajouter à la liste des contextes.
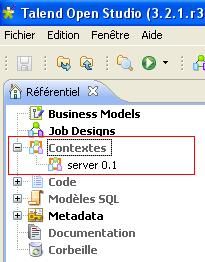
Vous pouvez refaire cette opération autant de fois que vous avez de groupes de contexte à définir.
N'ajoutez pas pour le moment les informations relatives aux bases de données, car Talend va pouvoir importer les informations de connexion automatiquement comme nous allons le voir dans le chapitre VI.
Pour utiliser ces variables, il suffit d'ajouter dans l'onglet « Context » du job, les variables de contextes nécessaires et d'appeler une variable de cette manière :
context.logFolderV. Définir les types de variables▲
Talend permet de définir les tailles par défaut des variables Java. Pour configurer cela, cliquez sur le menu « Fenêtre > Préférences ». Dans cette fenêtre, développez l'arborescence en cliquant successivement sur « Talend > Specific Settings > Default type and Length ».

Vous pouvez ainsi définir les longueurs par défaut du type String à une taille de 300.
Maintenant que vous avez défini les types et les longueurs des variables, cliquez sur « Metadata of TalendType » pour définir les relations types base de données / variables Java. Car par exemple, Talend va charger les données de type NUMBER (pour une base de données Oracle) dans une variable de type BigDecimal, alors que vous souhaitez plutôt que le type NUMBER soit mapper avec un type Integer Java (plus maniable).
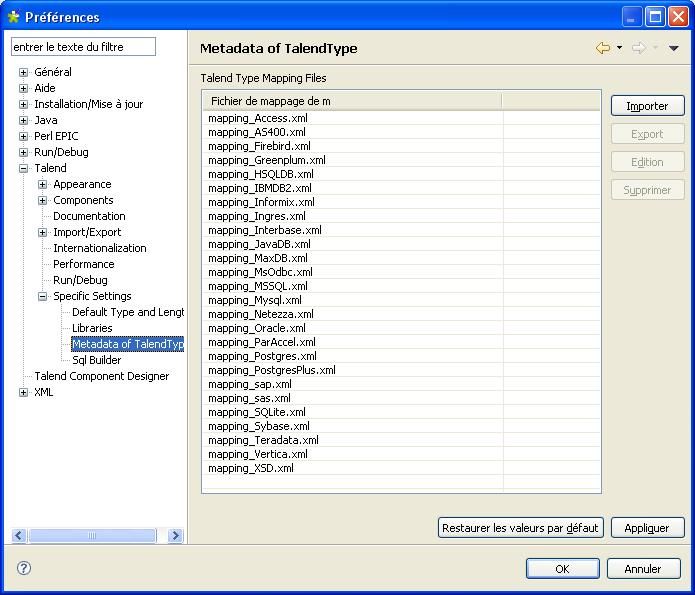
Dans cette fenêtre, vous pouvez voir une liste de fichiers XML qui mappent les types « base de données » avec les types Java.
Par exemple, on va modifier le mapping NUMBER -> BigDecimal d'une base de données Oracle pour obtenir NUMBER -> Integer
Double-cliquez sur le fichier mapping_Oracle.xml et recherchez la section suivante :
<talendType type="id_BigDecimal">
<dbType type="DEC" default="true"/>
<dbType type="DECIMAL"/>
<dbType type="NUMERIC"/>
<dbType type="NUMBER"/>
</talendType>Coupez la ligne :
<dbType type="NUMBER"/>et collez-la dans la section :
<talendType type="id_Integer">
<dbType type="INT" default="true"/>
<dbType type="INTEGER"/>
<dbType type="PLS_INTEGER"/>
</talendType>Repérez enfin la section :
<dbType type="NUMBER">
<talendType type="id_BigDecimal" default="true" />
</dbType>et changez la valeur du paramètre type par id_Integer.
Maintenant les valeurs de type NUMBER seront exportées/importées en Integer dans Talend à la place du type BigDecimal.
VI. Gérer les métadonnées▲
VI-A. Définir les connexions aux bases de données▲
Un ETL permet de récupérer des données de plusieurs sources différentes, de les transformer et de les recharger dans un entrepôt de données central. Nous allons donc maintenant définir les connexions aux bases de données.
Faites un clic droit sur « DB Connections » dans le menu de droite puis sur « Créer une connexion ».
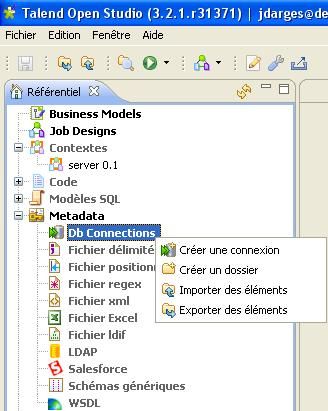
Renseignez le nom que vous voulez donner à la connexion.
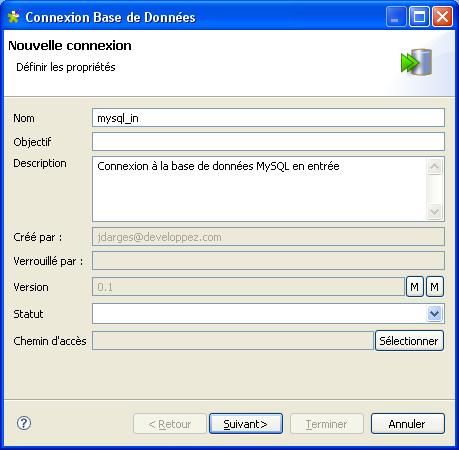
Après avoir cliqué sur [Suivant], renseignez toutes les informations relatives à la connexion.
Vous pouvez enfin tester la connexion en cliquant sur le bouton [Vérifier].
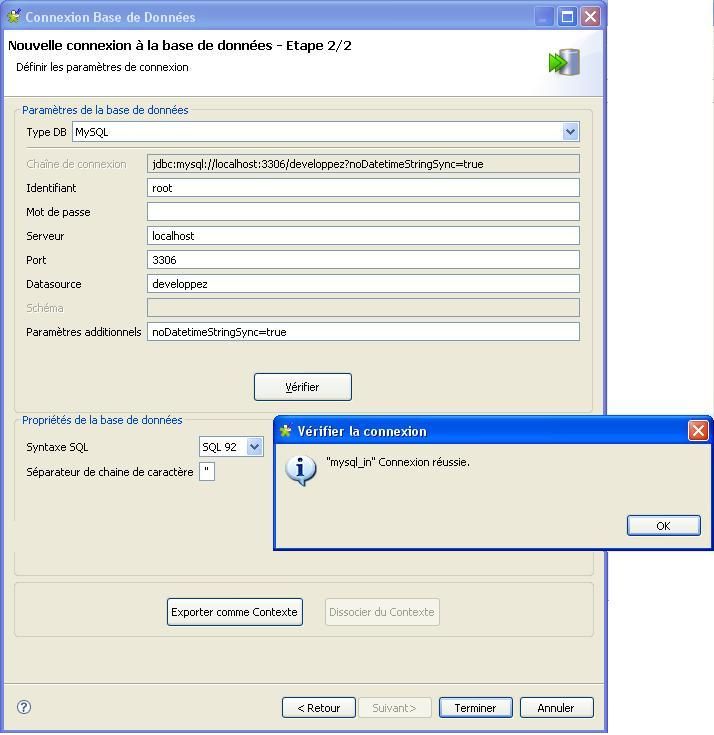
Maintenant, chose très importante à ce niveau, on va pouvoir exporter les variables liées à la connexion dans un groupe de contexte en cliquant sur le bouton [Exporter comme context].
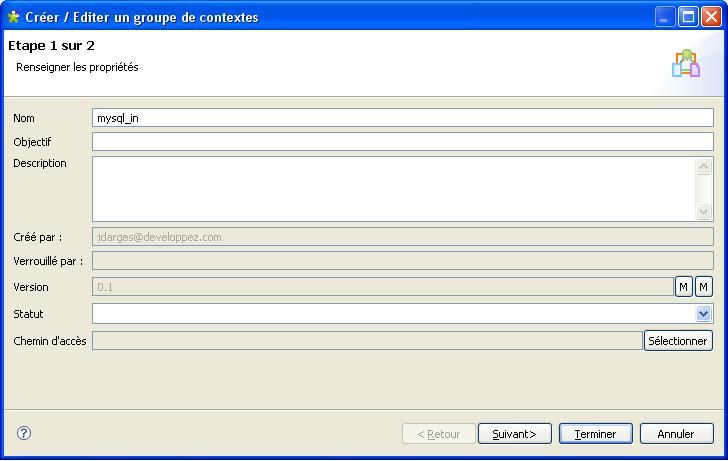
Comme dans le chapitre précédent vous allez pouvoir définir les valeurs de la connexion pour chaque environnement de travail.
Cliquez successivement sur le bouton [Suivant] puis sur l'onglet « Valeurs en table » ensuite, cliquez comme indiqué sur l'image :
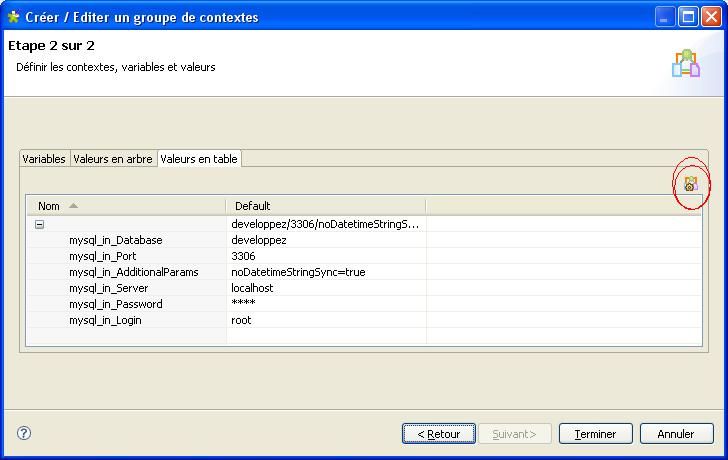
Pour la suite, reportez-vous au chapitre précédent.
Une fois les variables exportées dans un groupe de contexte, cliquez sur le bouton [Terminer]. La connexion s'est ajoutée aux métadonnées ainsi que le groupe de contexte en relation.
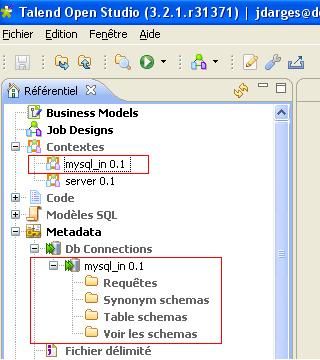
Vous pouvez maintenant récupérer le schéma des tables de la connexion précédemment paramétrée. Pour cela, faites un clic droit sur la connexion voulue puis sur « Récupérer le schéma »
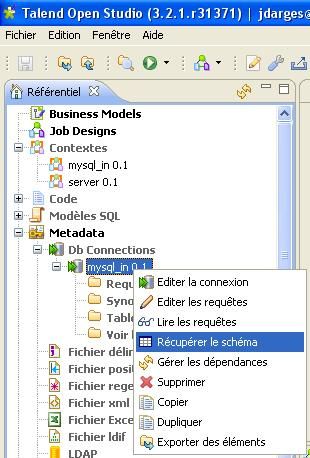
Une fenêtre va vous demander quel référentiel utiliser pour se connecter à la base de données : à vous de choisir.
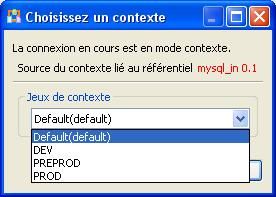
Vous pouvez ensuite choisir quels objets importer. Pour l'exemple, je ne vais importer que le schéma des tables.
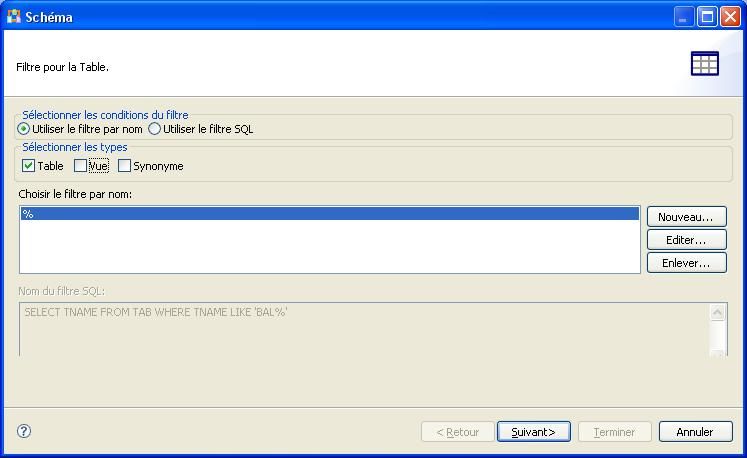
Cochez ensuite les tables à importer et cliquez sur le bouton [Suivant].
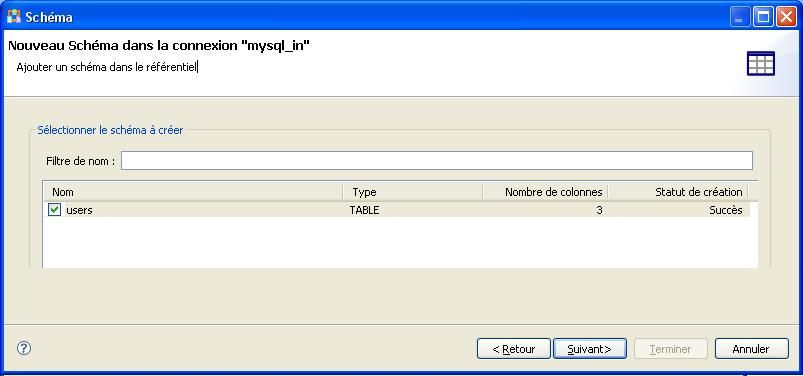
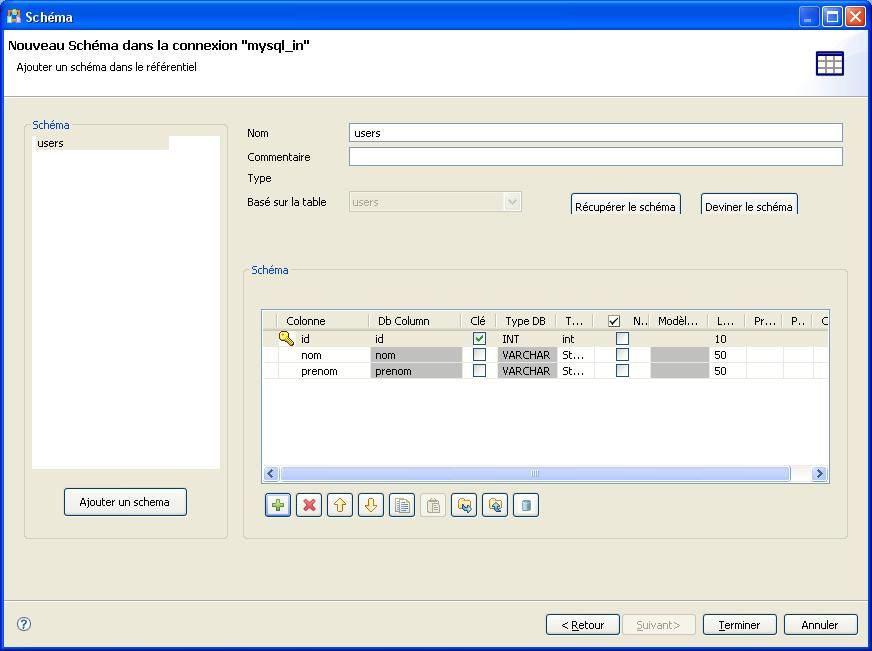
Définissez le schéma des tables si nécessaire et cliquez sur le bouton [Terminer].
Les schémas des tables ont été ajoutés aux métadonnées et pourront être utilisés dans les jobs.
VI-B. Définir les fichiers sources/cibles▲
Un peu comme les connexions aux bases de données, on va ajouter les fichiers sources/cibles dont le schéma n'évoluera pas au cours du temps et qui seront utilisés de façon répétitive dans les jobs.
Dans l'exemple qui va suivre, on va ajouter un fichier de type délimité.
Faites un clic droit du « Fichier Délimité » dans le menu de gauche dans la partie Metadata, puis cliquez sur « Créer un fichier délimité ».
Dans la fenêtre qui s'affiche, renseignez le nom du fichier (il peut être différent du nom physique du fichier dans le file system). Cliquez sur le bouton [Suivant].
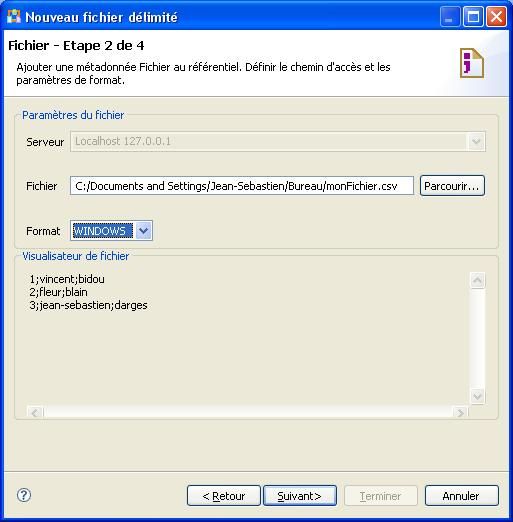
La fenêtre qui s'affiche maintenant va vous permettre de visualiser les données du fichier dont on veut récupérer le schéma.
Évitez de charger un fichier de plus de 1 Mo, car plus le volume sera important et plus Talend risque d'avoir du mal à charger ce fichier et à récupérer son schéma. Privilégiez un fichier peu volumineux.
Après avoir cliqué sur le bouton [Suivant], la fenêtre suivante s'affiche et vous permet de paramétrer le fichier à savoir : l'encodage, le séparateur et tout un tas d'autres choses que je vous laisse découvrir et qui n'ont pas besoin d'être expliquées.
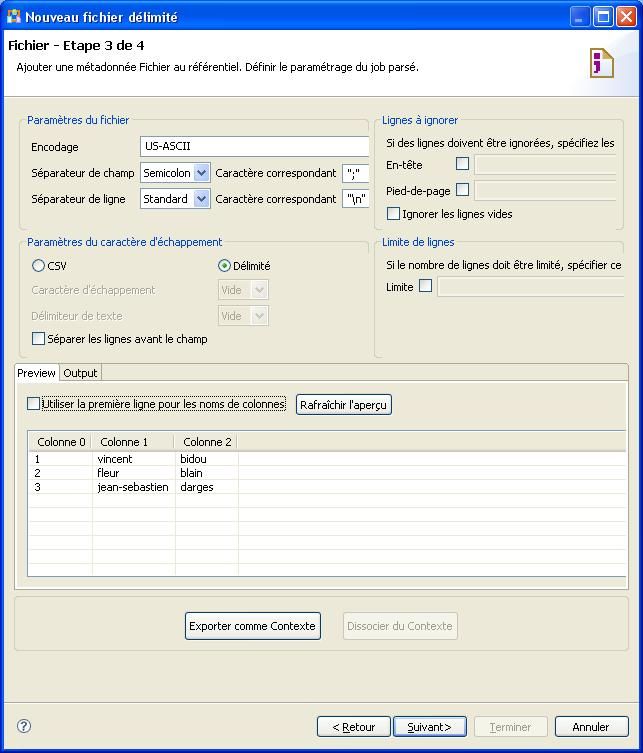
La fenêtre suivante permet de définir le schéma du fichier. Par défaut, Talend propose un schéma qu'il a automatiquement récupéré en fonction des données présentes dans le fichier.

Pour finir, cliquez sur le bouton [Terminer]. Le schéma du fichier s'est ajouté aux métadonnées.
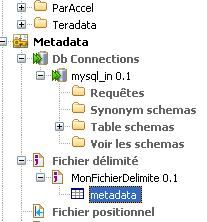
Faites de même pour tous les flux de données entrant et sortant.
Vous pouvez ajouter des schémas génériques qui n'auront pas une étiquette attachée du genre « schéma de fichier délimité » ou encore « schéma de fichier XML ». Ces schémas pourront être utilisés dans n'importe quel composant.
VI-C. Utilisation des métadonnées▲
Vous avez pu ajouter de nouveaux schémas dans les métadonnées et vous vous demandez à quoi cela va servir ? Tout simplement à ne pas redéfinir à chaque fois dans chaque job le schéma des composants.
Admettons que vous allez utiliser plusieurs fois la table « Users » de la base de données Mysql_in, que j'ai définie plus haut, dans plusieurs jobs. Ce serait dommage d'avoir à redéfinir le schéma de la table à chaque utilisation d'un tMySQLInput.
Pour utiliser la connexion à la base de données MySQL et le schéma de la table « Users », suivez la procédure indiquée ci-dessous :
faites un glisser/déposer de table Users de la connexion MySQL définie dans les metadatas. Talend va vous demander quel type de composant sera utilisé avec cette table : choisissez tMysqlInput
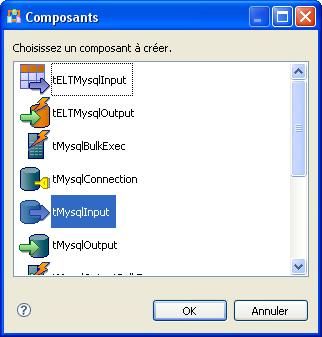
Une seconde fenêtre s'affiche pour savoir si vous voulez ou non importer les contextes relatifs à la connexion à la base de données. Cliquez sur le bouton [Ajouter].
Le composant ajouté, vous pouvez double-cliquer sur ce dernier pour voir son paramétrage :
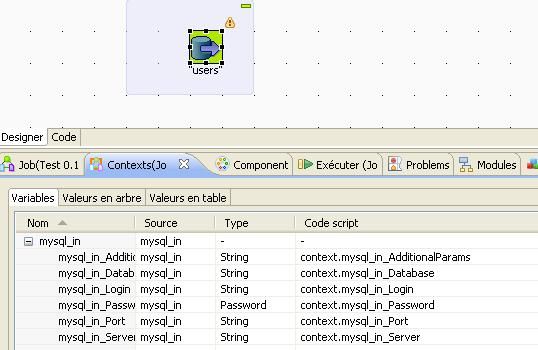
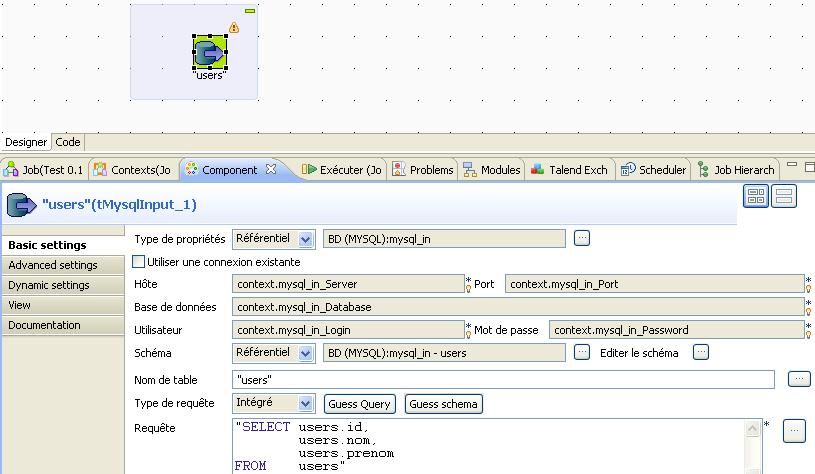
On voit alors que la base de données est issue du référentiel (metadata) et que le schéma de la table est lui aussi issu du référentiel. Talend a même généré automatiquement la requête de récupération de l'ensemble de la table.
En une minute : en faisant uniquement un glisser/déposer et deux clics vous avez créé une connexion à la table Users de la base mysql sans coder une seule ligne !
À chaque fois que vous utiliserez un composant, vous pourrez ainsi faire appel aux métadonnées du référentiel et donc ne plus avoir à définir manuellement les schémas des composants. Soit un gain de temps non négligeable.
VII. Gestion des logs▲
Il ne faut pas oublier de gérer les logs de vos jobs Talend. On oublie trop souvent ou trop tard de générer des logs d'application. On va donc voir comment générer automatiquement des logs dans vos jobs.
Cliquez successivement sur « Fichier > Edit project Properties ».
Dans la fenêtre qui s'affiche, développez le menu de gauche en cliquant sur « Job Settings » > « Stats and logs ». Cochez ensuite la case « Utiliser les logs » (tLogCatcher) puis choisissez où sauvegarder les logs.
Je vous conseille de le faire dans un fichier, car si vous sauvegardez vos logs dans une base de données rien ne dit que cette dernière ne plantera jamais. Alors qu'un fichier est lisible depuis n'importe quel poste et le risque de plantage lié au logs sera moindre.
Exemple :
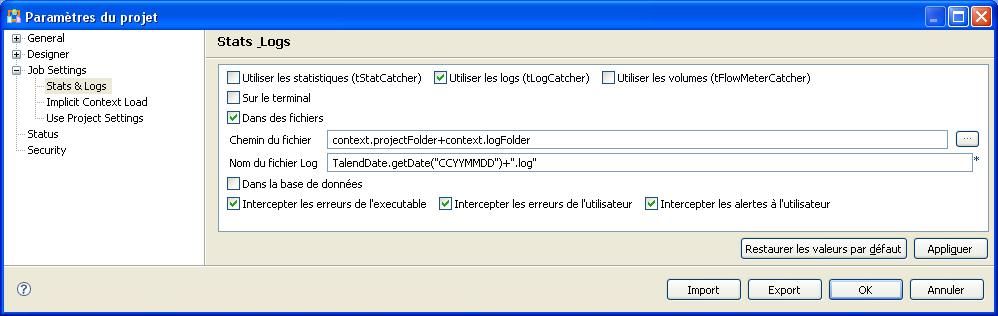
Explications
J'ai renseigné dans le champ « chemin du fichier » (dossier de sauvegarde des logs) context.projectFolder+context.logFolder, car précédemment j'ai ajouté un groupe de contexte « server » avec les variables projectFolder et logFolder. La combinaison des deux variables me donne le dossier de sauvegarde des logs.
Pour ce qui est du nom des logs plusieurs options s'offrent à vous :
- Soit vous indiquez un nom de fichier fixe par exemple mesLogs.log. Dans ce cas, tous les logs iront dans ce fichier ce qui pourrait poser des problèmes de taille ;
- Soit vous indiquez un nom de fichier par rapport à la date courante (comme j'ai fait) : TalendDate.getDate(« CCYYMMDD »)+« .log ». Les logs seront sauvegardés par jour dans un fichier avec un nom de type 20100222.log ;
- Soit vous choisissez un fichier de log pour chaque job et dans ce cas, il faut utiliser la variable « jobName » que vous pouvez concaténer avec le nom du projet par exemple et à la date (pour faire compliqué :)) : projectName+« . »+jobName+« _ »+TalendDate.getDate(« CCYYMMDD »)+« .log ».
J'ai préféré utiliser les variables de contexte, car cela permet de passer d'un environnement de travail à l'autre sans problème de chemin invalide.
Maintenant, si vous ajoutez un nouveau job, vous aurez ceci dans l'onglet « Job » partie « Stats and Logs » :
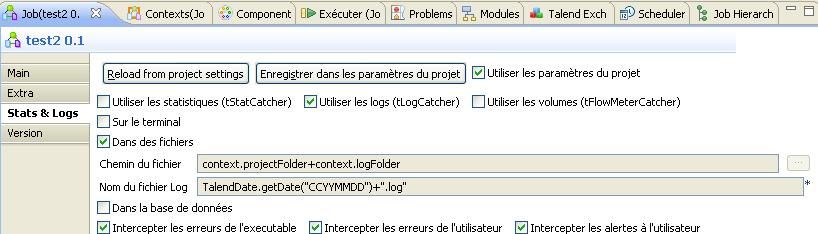
Par contre le job n'a pas automatiquement ajouté les contextes propres à la configuration des logs. Il faut donc maintenant le faire.
Pour cela, cliquez sur l'onglet « Contexts » puis sur le bouton à côté de la flèche bas :
Choisissez ensuite les deux variables de contexte logFolder et projectFolder du groupe server.
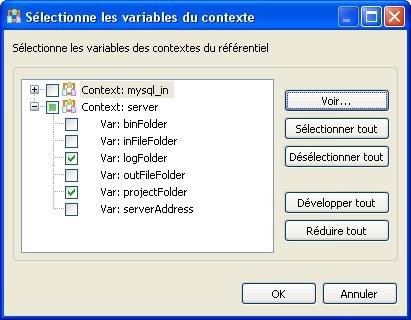
Une autre fenêtre s'affiche quand vous cliquez sur [OK]. Cette fenêtre permet d'importer les environnements de travail.
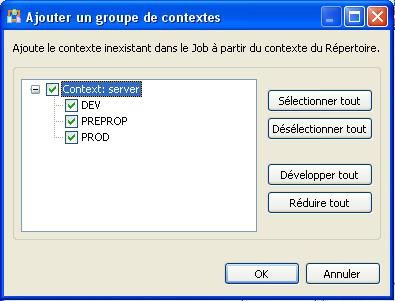
Une fois terminé, les variables de contexte relatives aux logs seront ajoutées et vous pourrez alors commencer à développer vos jobs.
Les fichiers de logs pourront ressembler à cela :
2010-02-17 15:20:08;E2BzGt;E2BzGt;E2BzGt;MONPROJET;test2;Default;6;Java Exception;tFileInputDelimited_1;java.io.FileNotFoundException:C:\Documents and Settings\Developpez\Bureau\monFichier.csv (Le fichier spécifié est introuvable);1On a ainsi l'endroit où le process a planté : MONPROJET (le nom du projet), test2 (le nom du job). Les informations sur le contexte utilisé : Default et l'erreur Java.
On peut faire exactement la même chose pour les métriques des jobs (combien de données entrées, combien de données traitées…) et leurs statistiques (heure de début, heure de fin et temps d'exécution) .
Exemple de fichier des statistiques :
2010-02-17 15:26:02;WeW17F;WeW17F;WeW17F;2400;MONPROJET;test2;_kR0M0BvNEd-WqpfVv2WXGQ;0.1;Default;;begin;;
2010-02-17 15:26:02;WeW17F;WeW17F;WeW17F;2400;MONPROJET;test2;_kR0M0BvNEd-WqpfVv2WXGQ;0.1;Default;;end;success;47VIII. Conclusion▲
Pour bien commencer à développer un projet sous Talend, voici les sept étapes essentielles :
- Choisir des postes de travail performants pour une meilleure souplesse de développement ;
- Choisir un serveur encore plus performant que les postes de travail ;
- Lister les variables qui seront utilisées dans le projet ;
- Ajouter les variables de contexte se basant sur la liste précédente ;
- Ajouter les connexions aux bases de données ;
- Ajouter les schémas sources et cibles (metadata) ;
- Ne pas oublier les logs.
Maintenant que vous avez bien retenu ces étapes, à vos PC et bon développement.
IX. Remerciements▲
Je remercie jacques_jean pour ses remarques et sa relecture.